
让我们来做一个流浪地球中的MOSS
科幻一直是我喜欢的题材。最近看了流浪地球2,发现这是一部半科幻半写实的电影。
里面很多看似高超的技术现实中已经有雏形存在。比如无人机蜂群、电子狗、外骨骼等。
 无人机蜂群:5G、高性能电池、自主协同控制、以及人工智能相结合的产物
无人机蜂群:5G、高性能电池、自主协同控制、以及人工智能相结合的产物
 机器狗:狗和人一样有被人工智能替代的风险(图片来源:互联网)
机器狗:狗和人一样有被人工智能替代的风险(图片来源:互联网)
 游戏与现实中的外骨骼对比:喜欢玩《死亡搁浅》游戏的可以去蜂鸟即配体验生活
游戏与现实中的外骨骼对比:喜欢玩《死亡搁浅》游戏的可以去蜂鸟即配体验生活
电影中最科幻的技术要数行星发动机、太空电梯、以及人工智能MOSS(数字生命体属于MOSS的应用程序)。
 流浪地球2中MOSS剧照
流浪地球2中MOSS剧照
行星发动机太大,太空电梯太高,唯独人工智能MOSS还可以山寨一下。
 流浪地球2中MOSS剧照
流浪地球2中MOSS剧照
不过罗马不是一天建成的,我们第一步也只山寨自然语言交互系统部分。即人对MOSS说话,MOSS根据说话的内容通过语音回复。效果就如同打电话一样。
为了山寨这样一个系统,我们需要实现语音识别、自然语言理解、以及文字转语音这三个机器学习模块。在《关于GPT,人工智能,以及人的一些思考》这篇文章中我们讨论了GPT。这个模型可以用于自然语言理解。当然,为了追求对话质量,在山寨MOSS里我会直接使用GPT3而不是我自己训练的乞丐模型。
有了自然语言理解,我们还需要实现 语音识别(STT) 和 文字转语音(TTS) 这两个模块。在深度学习大规模应用之前,无论是语音识别还是文字转语音,都是艰巨的任务。
记得以前在微软亚洲研究院做数据智能方面的实习,结束时实习导师请我们吃饭。我好奇地问她为什么从语音识别转行到数据智能。她半开玩笑地说道语音识别太难了,数据智能更容易在实际产品中看到成果。
作为微软亚洲研究院的第一位女性研究员,我不认为她是那种因为一个领域“太难了”而转行的人。而作为世界上第一个中英混杂文语转换系统“木兰”的发明人,我相信她对语音转换这一领域挑战性的洞见。
时间往后拨若干年,现在我这个对语音识别领域一窍不通的人也敢来试试这个领域的应用了。导师是声学背景出身,她当年是从声学入手来解决这两个问题的。如果按这个方法入手,打基础就可以把人劝退。
现在有了深度学习以及开源环境的加持,我们可以很大程度上利用现有资源山寨MOSS交互系统。由于是人机语音对话系统,通过视频展示更加方便直观。由于合成的语音是女声,我把它取名为femoss。
下面我们直接看效果。
Femoss 语音对话演示系统Femoss:需要开启声音观看视频,请忍受我的口音
细节讲解
如果你对实现细节感兴趣,那么请接着读下去。但如果你是深度技术宅,接下来的内容对你来说太浅显了。因为目前这个系统只是完成了最最基本的功能,几乎没有任何技术含量以及原创价值。
Femoss的整个系统的框架大概如下:
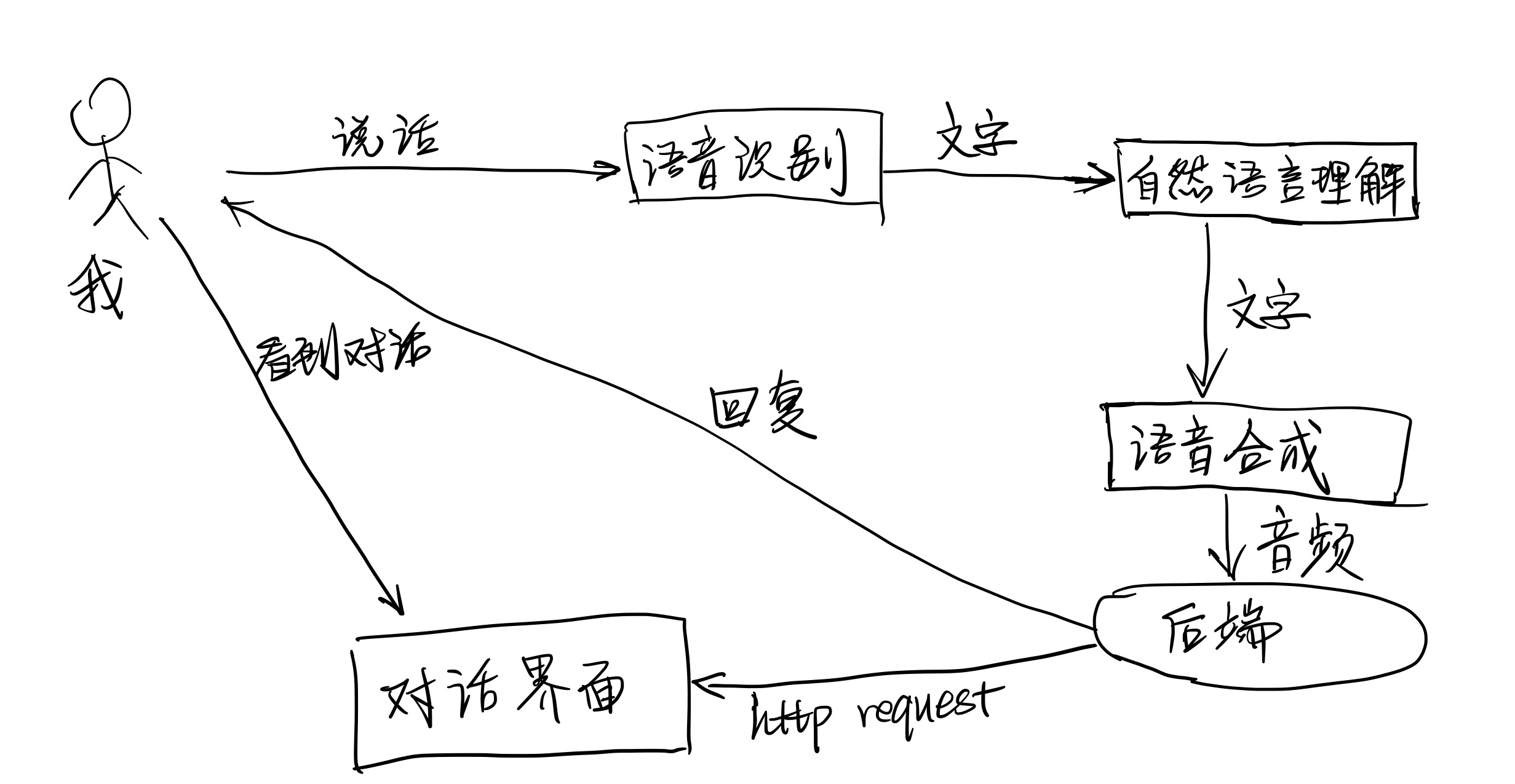 系统结构
系统结构
整个系统还有很多可以提升的地方。大概可以分为如下几个方面:
- 语音识别。
- 语音合成。
- 自然语言理解与命令执行。
语音识别
这一部分我直接使用了现成的语音识别模型(wav2vec)来整合进系统,模块局限性还很大。
从演示视频中可以看出,系统(模型)对我带有口音的英语识别不是很好,有个别单词出现了误听。比如the听成了a,today听成了to day。
这在两个方面可以进行改进:fine tune以及使用更好的decoder。
Fine tune即提供自己的声音以及标注数据来进一步训练模型。这样可以使得模型“适应”个人的口音。当然,也可能导致更难识别别人的语音。如果要有一个鲁棒的模型,本质还是要用不同口音的数据训练。
Decoder的主要功能是将声学模型预测出的音素序列转换为对应的单词序列,并对单词序列进行排列和整合,生成最终的文本输出。
语音识别模型的直接输出是潜在的识别出的一串音素的概率分布。如果每次只选取可能性最高的音素,那么很可能组合起来的文字并不是最合适的。这时候就需要用到语言模型来计算一串音素可能组成的句子中最靠谱的那一个(即联合概率最高的一种组合)。当输入的语音很长,那么潜在的音素组合数量就会成指数上升。这时候一个个组合去估计可能性就很慢了。这时候我们就需要使用一种叫做”集束搜索(beam search)”的方式来减少考虑的候选组合。
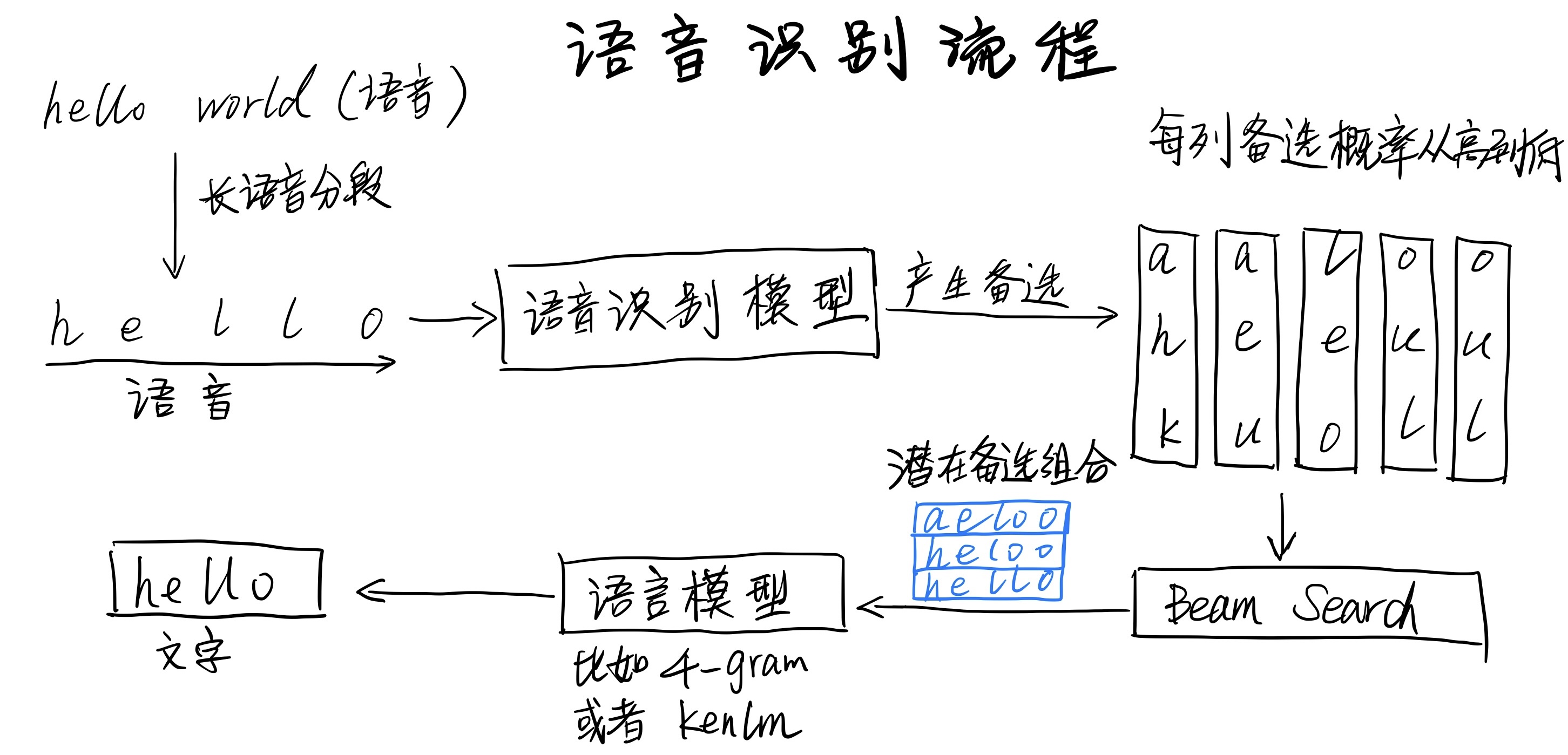 语音识别流程
语音识别流程
如果要让MOSS能够识别中文或者多种语音,还需要使用更强大的语音识别模型。
中文语音识别非常困难。这是因为汉字是表意语言,而拉丁语系是表音语音。表意语言的大部分信息是由形而非音传递。因此无论如何识别语音,系统无法获得所有信息。
我们看看现代语言学之父赵元任先生的《施氏食狮史》:
《施 (shī) 氏 (shì) 食 (shí) 狮 (shī) 史 (shǐ) 》 石 (shí) 室 (shì) 诗 (shī) 士 (shì) 施 (shī) 氏 (shì),嗜 (shì) 狮 (shī),誓 (shì) 食 (shí) 十 (shí) 狮 (shī)。 施 (shī) 氏 (shì) 时 (shí) 时 (shí) 适 (shì) 市 (shì) 视 (shì) 狮 (shī)。 十 (shí) 时 (shí),适 (shì) 十 (shí) 狮 (shī) 适 (shì) 市 (shì)。 是 (shì) 时 (shí),适 (shì) 施 (shī) 氏 (shì) 适 (shì) 市 (shì)。 施 (shī) 氏 (shì) 视 (shì) 是 (shì) 十 (shí) 狮 (shī),恃 (shì) 矢 (shǐ) 势 (shì), 使 (shǐ) 是 (shì) 十 (shí) 狮 (shī) 逝 (shì) 世 (shì)。 氏 (shì) 拾 (shí) 是 (shì) 十 (shí) 狮 (shī) 尸 (shī),适 (shì) 石 (shí) 室 (shì)。 石 (shí) 室 (shì) 湿 (shī),氏 (shì) 使 (shǐ) 侍 (shì) 拭 (shì) 石 (shí) 室 (shì)。 石 (shí) 室 (shì) 拭 (shì),氏 (shì) 始 (shǐ) 试 (shì) 食 (shí) 是 (shì) 十 (shí) 狮 (shī) 尸 (shī)。 食 (shí) 时 (shí),始 (shǐ) 识 (shí) 是 (shì) 十 (shí) 狮 (shī) 尸 (shī),实 (shí) 十 (shí) 石 (shí) 狮 (shī) 尸 (shī)。试 (shì) 释 (shì) 是 (shì) 事 (shì)。

不是说不可能识别,只是太难了…
在语音识别上,表意语言很难被识别,但是在自然语言处理上,表意语言又比表音语言有潜在优势,因为它还额外提供视觉信息。我们对中文自然语言处理一直在使用表音语言的方法。即先把句子分词使得我们获取类似单词的单位。我们是否应该做分字而不是分词呢。
如果我们把文字看成图像,用视觉的方法处理中文自然语言,是不是会有意想不到的效果呢?
 侠客行剧照:刻在石壁上的太玄经
侠客行剧照:刻在石壁上的太玄经
在金庸先生的《侠客行》中有一种绝顶武功叫做《太玄经》。这种武功秘籍传闻隐藏在侠客行这首诗中。无数武林高手竞相研习这门武功但始终无人参透。只有石破天这个不识字的人把文字看作是图像从而领悟出了这门绝顶武功。
不知道未来的自然语言算法是不是也像石破天那样,大字不识却能以异于常人的角度领悟自然语言那无比复杂的规律。
这个思路其实Lecun Yann在三十年前探索过了,只不过他当时只是用于文字识别而不是复杂得多的文字理解。
 图灵奖得主Lecun Yann在1993年代尝试的数字识别
图灵奖得主Lecun Yann在1993年代尝试的数字识别
语音合成
语音合成我是使用的一个叫做Silero的模型。这是一个很好用且速度很快的语音合成模型,可以用于实时场景。可惜的是,Silero模型没有中文语料。
在演示视频中,我们可以看到系统的反应很慢。这由两方面因素造成:
- 我刻意让系统等待我把话说完。只有当我没有声音超过3秒后系统才会进行处理。
- 我的笔记本没有GPU,所有的模型推理都是通过CPU来运算的。为了提高语音合成速度,我做了一些额外处理,比如把文字分段然后按流水线的方式来进行处理。当系统播放第一段语音时,后台再处理后续的语音合成。
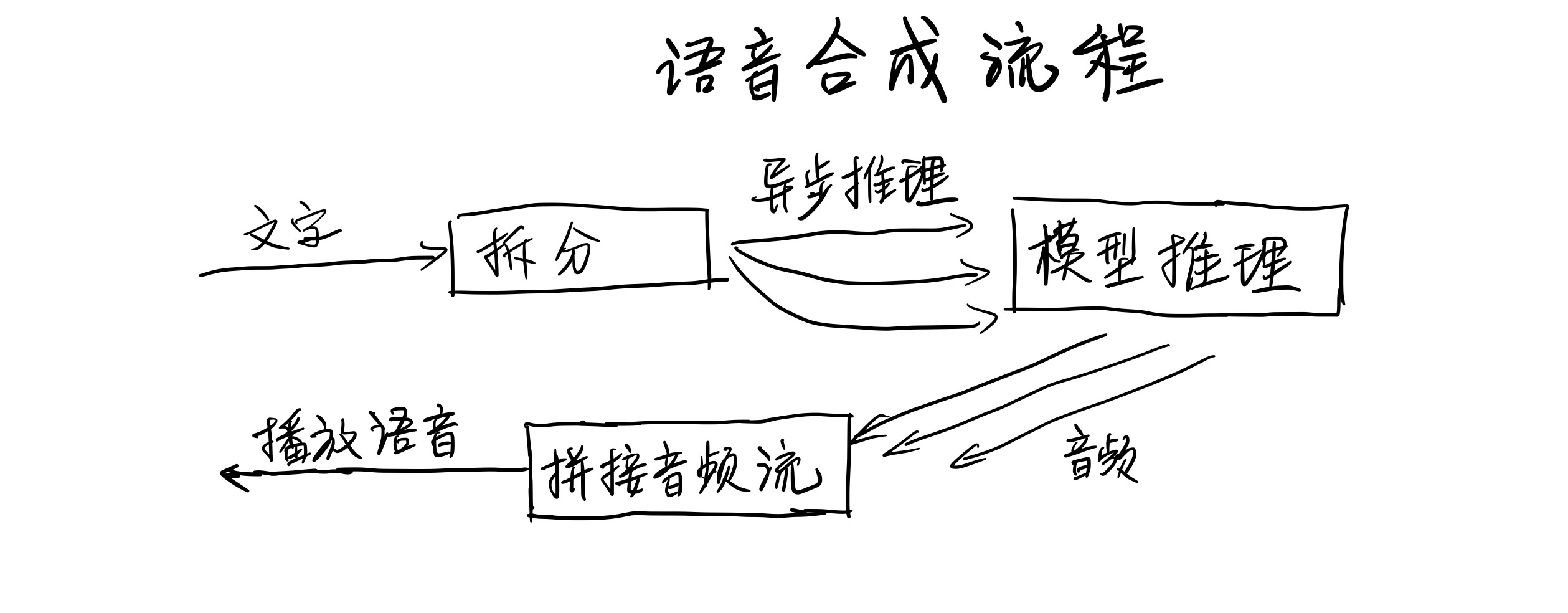 语音合成流程
语音合成流程
这一部分的后续提升没有什么新意,就是不断提高合成的质量,以及进行中文语音合成。
自然语言理解和命令执行
这是整个系统最有扩展性的部分。目前这个模块基本依赖于OpenAI的GPT API。这个API很强大,加上最新的ChatGPT的API,基本对话是没有问题的。
 一幅图概括目前这个模块的状态。按照新创公司的标准,不知我这个系统是否已经达到“企业级”了。
一幅图概括目前这个模块的状态。按照新创公司的标准,不知我这个系统是否已经达到“企业级”了。
后续计划
MOSS并不只是一个对话机器人。它应该是一个中枢系统,可以调动各种工具以及控制物理世界中的设备。比如电影中我们看到MOSS可以控制行星发动机,各种摄像头,以及大量的无人机等。
这是我接下来想实现的功能。很有挑战性,也很有意思。
如果还有额外精力与时间的话,我会深入看看各个模型的具体实现,看看有什么可以功能扩展的地方。
注:本文涉及到的领域之前对我来说是完全陌生的。我在过去两个星期抽空学到的知识难免不准确。如果有错误还请各位领域专家指正。.
Leave a comment