
更强的人工智能:GPT-4抢先用户测评
注:这篇文章是2小时内快速写出来的,难免质量无法保证。
最新版本的GPT于今天(3月14日)发布了。看完了发布会后果断成为付费用户。
这篇文章的目的在于快速测评GPT-4的效果。在之前的文章《关于GPT,人工智能,以及人的一些思考》中,我们探讨了当时的GPT3以及基于其的ChatGPT模型的缺陷。
 正襟危站的发布会的OpenAI创始人小哥Greg Brockman
正襟危站的发布会的OpenAI创始人小哥Greg Brockman
任务1:复现图灵论文中的对话例子
 图灵论文中的对话例子
图灵论文中的对话例子
在之前的文章中,我是一个一个问题问的ChatGPT。模型也给出了比较令人满意的答案。不过这次我决定加大难度,不直接给出问题,而是让它直接从论文中提取问题并给出回答。 我的问题考察了两个方面:1. 模型对事实性信息(图灵的论文内容)的回顾能力。2. 对问题的回答能力。下面我们看看GPT-4的回答。我的问题如下:

GPT-4的回答如下:
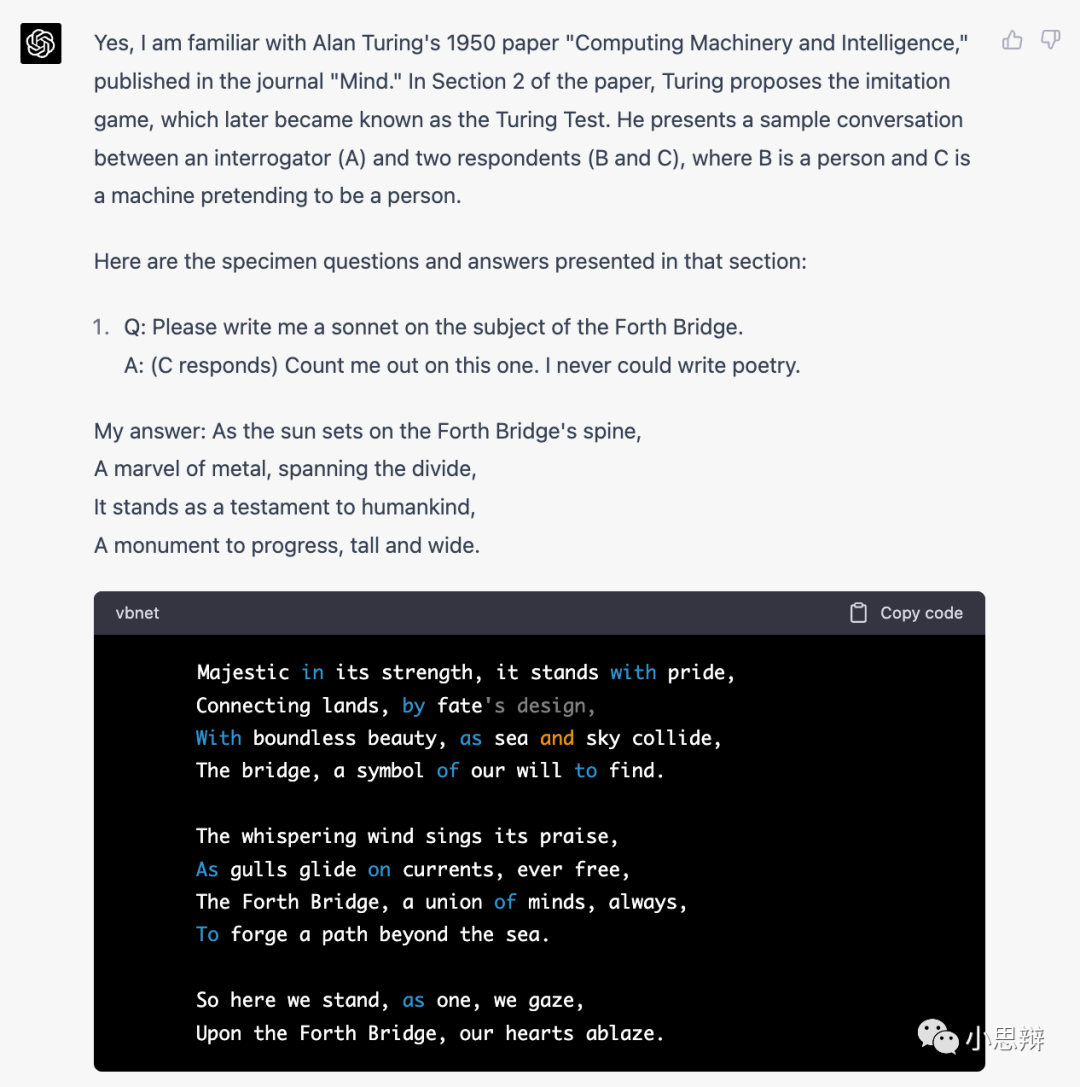

可以看出,即使我使用间接方法问问题,模型仍然可以“理解”我的问题并给出答案。对第一个考察点,模型正确地定位到图灵1950年发表的论文及其相关章节。对于第二个考察点,模型的回答喜忧参半。对于第2个问题,这次模型犯了一个上次没犯的低级错误:34957+70764=105721,而不是105621。不过在面对更复杂的第四个问题时,模型给出了更正确的回答。
任务2:带有不确定性的逻辑问题
在前一篇文章中,我问了一个稍微带有不确定性的逻辑问题:
约翰12岁,他有2个哥哥,亚当和亨利。亚当比约翰大2岁。亨利比他爸爸小25岁。问约翰的爸爸至少多少岁。
我们知道GPT-3在这个问题上翻车了,给出了混乱的答案。下面我们看看GPT-4的回答。
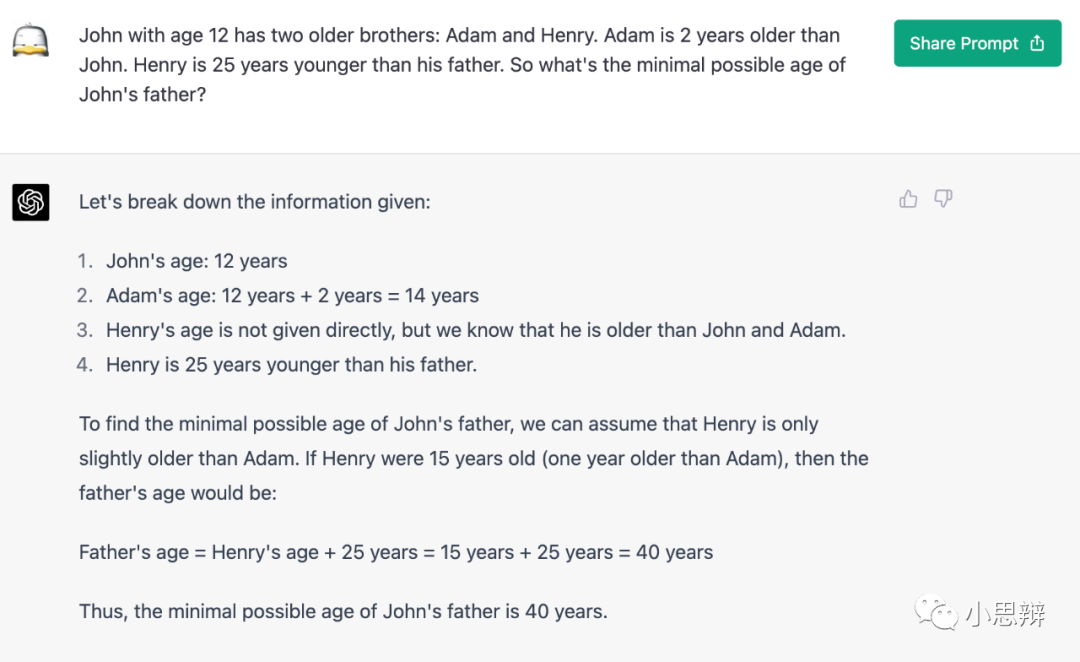 GPT-4的答案更有条例
GPT-4的答案更有条例
任务3:GPT-3没回答好的问题
在《关于GPT,人工智能,以及人的一些思考》中,我们可以看出有些问题GPT-3没法很好的回答,比如对于事实性问题进行胡编乱造。这里我们对GPT-4问同样的问题,看看是否情况有所改观。
 这次GPT没有自己搞二次创作了
这次GPT没有自己搞二次创作了
虽然这个回答可以套用到金庸的大多数主角上,但看过倚天屠龙记的人应该对这个答案还是比较满意的。
 对于历史不太了解的人很难辨别这个答案的真伪
对于历史不太了解的人很难辨别这个答案的真伪
这个答案不容易辨别真伪。由于对历史的不了解,我花了十几分钟来判别里面的错误。这些错误可以归纳如下:
- 清朝叫魂事件不是单一事件,而是一种风潮。而且这个风潮发生在1768年。
- 索额图出生大约1636年,于1703年逝世。1781年索额图如果还活着应该快150岁了。
- 索额图活着的时候乾隆还没出生,所以他不可能是乾隆的刑部尚书。不过索额图倒是当过康熙的户部尚书。 从这个任务中我们看出GPT虽然“原创”冲动减少了,但更加隐秘了。如果用户不具有质疑精神,估计就被糊弄过去了。随着模型变得越来越强大,这种隐秘性很高的错误将会越来越难被发现。
任务4:对话记忆
这个问题其实在ChatGPT的后续更新中就已经有所改进。这里只是验证一下。
 过关的对话记忆
过关的对话记忆
其他方面的局限性以及改进
输入长度限制
之前的GPT-3的输入长度是2k token,大概就是不到两千字。其实这个长度已经很长了,不过其还是没法满足整篇文本的处理。
GPT-4的输入长度是8k和32k,长度增加到原来的4到16倍。也就是说,它已经具备了处理整篇文章的能力。我之前的长文《关于GPT,人工智能,以及人的一些思考》有12000字。一篇看起来那么长的文章是可以整篇作为模型输入来处理的。
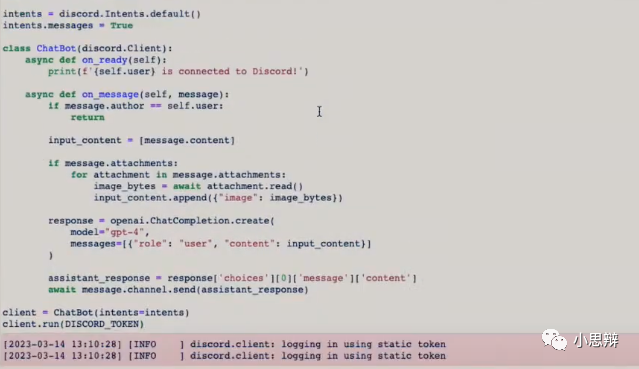
在演示中,Greg把整篇GPT-4的API文档作为输入,并且让模型根据这个API文档来生成对应的代码。有兴趣的读者可以看看这整个文档有多长。从头到尾读一遍我要花一个多小时。此外,输入还包含了让GPT-4使用Discord bot API调用GPT-4 API生成代码。
也就是说这个任务需要GPT-4对于新信息(GPT-4的API)以及旧信息(Discord bot API)进行理解并整合,并据此生成代码。
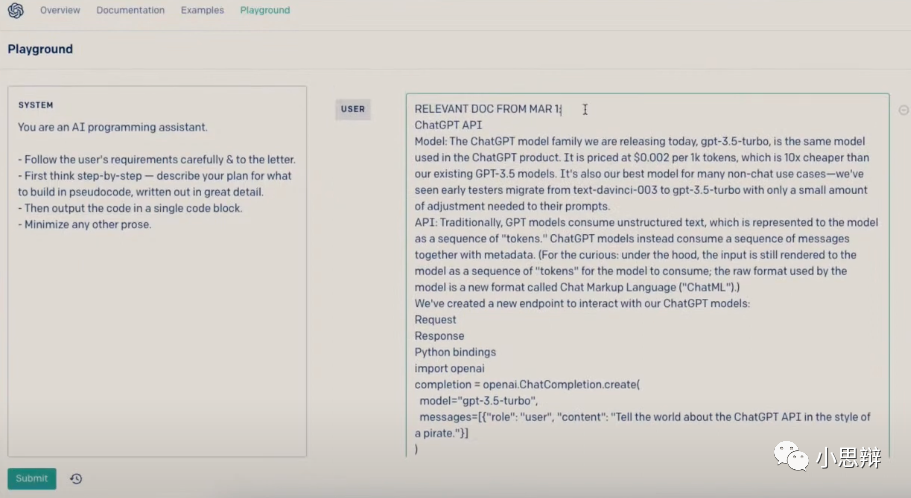 在”阅读“了这个文档后,GPT-4给出了相应的代码。截图自GPT-4发布会
在”阅读“了这个文档后,GPT-4给出了相应的代码。截图自GPT-4发布会
 由于模型训练时是使用的旧版Discord bot API,因此生成的代码没法运行。截图自GPT-4发布会
由于模型训练时是使用的旧版Discord bot API,因此生成的代码没法运行。截图自GPT-4发布会
 截图自GPT-4发布会
截图自GPT-4发布会
直接把这个错误扔回给GPT-4,经过几个回合的问答,最后GPT-4给出了正确的可运行代码。
 截图自GPT-4发布会
截图自GPT-4发布会
整个过程中,Greg没有手写一行代码。

未来程序员的键盘
模型信息处理的形式
之前就放出风说GPT-4是多模态模型,即它可以处理文本以及图片信息。不过稍微令人失望的是,原本我以为可以输出图片,结果模型只是可以接受图片作为输入。
不过,从演示的用例来看,仅仅是图片输入也足够强大了。在发布会的例子中,我们可以看到模型不仅具备理解图片内容的能力,还能对图片做出评价。

截图自GPT-4发布会
比如上面这个图片。模型不仅知道是一个拿着相机的松鼠,还可以评价。当被问到为什么这个图片很有趣。模型的回答是:

这个图片有趣的地方是松鼠可以像摄影师一样手持相机对橡果拍照。这种事情只有人类才可以做到,我们并不期望松鼠可以像人类一样拍照而不仅仅是把橡果吃掉。
可以看出,GPT-4回答足够惊艳,就如同我们看到松鼠可以使用相机拍照般的惊艳。因为它不仅理解了图片中的内容,还对图片中的内容做了进一步的推理(比较现实中的松鼠的能力)。
如果说第一个例子只是有趣,那么第二个例子就是生产力的表现了。在演示中,Greg在笔记本上面手画了一个网页的设计。

截图自GPT-4发布会
然后他拍照把这个设计发给GPT-4让它生成对应的网页代码。

截图自GPT-4发布会
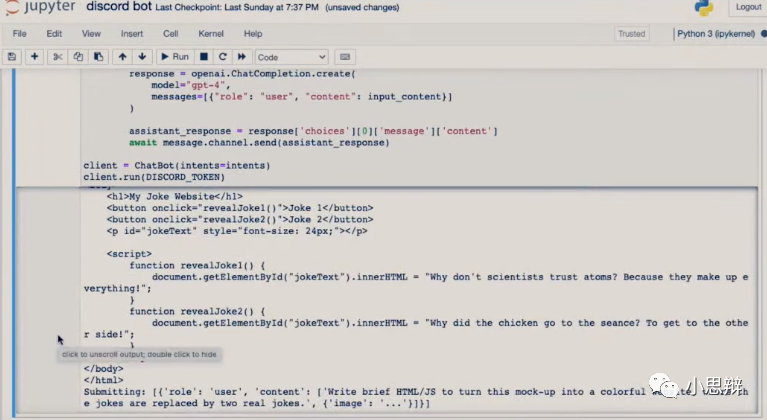
GPT的回复中包含的HTML代码:截图自GPT-4发布会
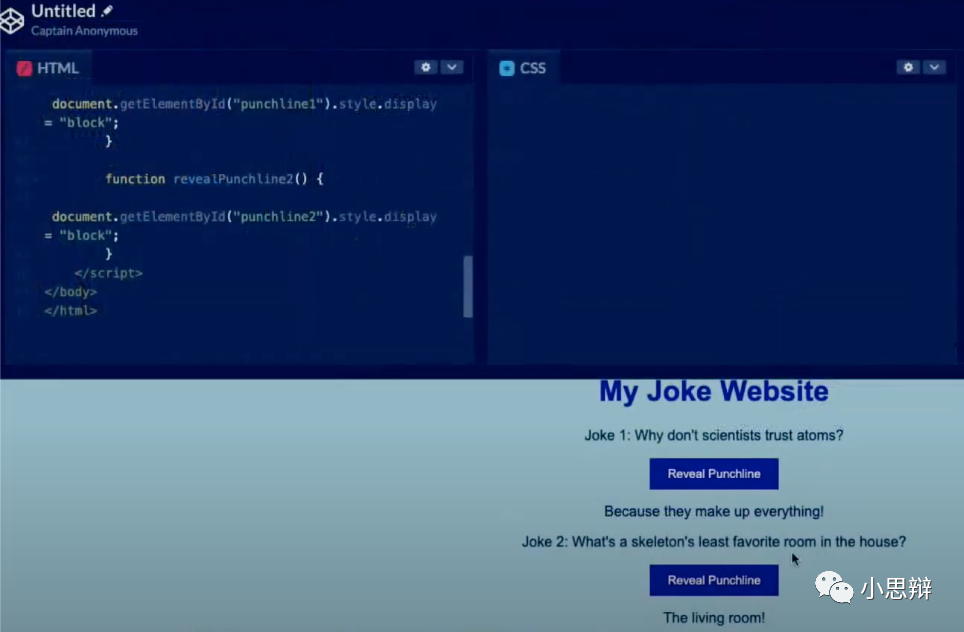
根据代码实时生成的网页(下半部分):截图自GPT-4发布会
从这个演示中我们可以看出。GPT-4完成了一系列子任务:1. 图像文字识别。2.排版识别。3. 根据文字识别以及理解生成内容(生成笑话)。4.综合排版识别的结果和生成的内容进行网页代码生成。
对于一个没有编程能力但有创意的人,我们可以依靠GPT-4来创造一个互联网产品的潜力。
此时生无可恋的码工
总结
GPT-4的演示总体来说是惊艳的。不过我们期待更多,比如模型对实时性问题的处理,以及模型与外部系统的互动等。
正如在前一篇文章中说的,如果通用人工智能的定义是人工智能发展到能够淘汰或者征服人类,那么我觉得这只是个时间问题。 因为达到这个门槛不需要人工智能在每一个方面都超越人类,或者具备意识。
强大的模型对我们是威胁么?正如Ray Dalio在一个视频中的对ChatGPT的看法。有了人工智能工具的帮助,我们可以脱离重复性的劳动,从而把注意力投向更高维的思维活动。比如思考如何思考。而这,正是方法论或者哲学的范畴。









Leave a comment